Video Translation With AI: How Your Videos Can Speak Every Language
Jack Clawson
Dictem Editorial
June 2, 2026
15 min
In Kürze
Discover how AI-powered video translation, voice cloning, and dubbing enable content teams and creators to launch multi-language videos in minutes, preserving voice brand identity while reducing traditional dubbing costs.
Inhaltsverzeichnis
- The New Era of Global Reach: Why Localizing Your Video Matters Today
- Understanding the Mechanics: How AI Video Translation Actually Works
- Beyond Simple Voiceovers: The Power of AI Voice Cloning and Dubbing
- Speed and Savings: Analyzing the ROI of AI Localization vs. Traditional Studios
- Step-by-Step Workflow: How Content Teams Localize Video at Scale
- Häufig gestellte Fragen
- Quellen
Wichtige Erkenntnisse
- AI translation technologies are growing rapidly, scaling to an industry worth over USD 2.34 billion in 2024.
- Advanced voice cloning maintains original speaker vocal identity and emotion across more than 38 distinct languages.
- Multimedia localization markets are expanding by 11.7% annually to keep up with international video demands.
- Automated translation platforms cut dubbing costs by up to 90% compared to renting traditional studio space.
The New Era of Global Reach: Why Localizing Your Video Matters Today
The digital video landscape has transformed completely, leaving English-only campaigns behind as content creators seek international audiences. Today, audiences expect content that feels tailor-made for their specific linguistic and cultural background. The numbers reflect this shift, with the global video localization market projected to expand from 3.5 billion dollars today to 6.5 billion dollars by 2033[1]. For podcasters, video creators, and media teams, localizing video is no longer a luxury strategy but an essential step to scale beyond hyper-competitive domestic markets.
Expanding Audience Pools and Driving Retention
Expanding into international markets requires more than just translating text. True engagement relies heavily on how comfortable your audience feels while consuming your content. For instance, research shows that 76% of German viewers will click away from a video if it only provides translated text subtitles instead of high-quality voice-overs[1]. This cultural preference highlights why relying solely on subtitles is a risky strategy, making the classic choice between subtitles versus dubbing a critical factor in direct audience retention.
Instead of treating translation as a final, rushed step in production, smart content teams are pivoting their operations. Building an efficient global distribution strategy means planning your foreign-language assets from the start. Adopting a strategic localization-first playbook helps creators publish simultaneously in multiple languages, maximizing initial launch momentum across YouTube channels, podcast networks, and streaming platforms.
Overcoming the Friction of Legacy Dubbing
In the past, the main barrier to video localization was the heavy friction of traditional dubbing processes. Media companies had to hire translation agencies, book physical recording booths, schedule voice actors, and manually sync audio tracks. Modern AI-native platforms eliminate this friction entirely. Platforms like Dictem use advanced technology to streamline the localization workflow, replacing expensive and slow studio dubbing workflows with cloud-based automation. Through its web application, Dictem Studio, Dictem allows creators to translate, re-voice, and adapt their content into over 100 languages while using voice-cloning technology to preserve the original speaker's unique tone.
| Comparison Aspect | Traditional Studio Dubbing | AI-Powered Video Localization |
|---|---|---|
| Turnaround Time | Weeks or even months of back-and-forth recording sessions | Minutes or hours of fully automated cloud processing |
| Cost Structure | High upfront studio rental fees and voice actor payroll | Scalable per-minute processing or predictable software subscriptions |
| Voice Continuity | Relies on finding local actors with similar voices | Maintains the original speaker's voice footprint across all languages |
| Workflow Effort | Requires manual synchronization, editing, and sound mixing | Provides automated script alignment and automated lip-syncing |
As the demand for global video continues to rise, content creators who adapt early will secure a massive competitive edge. By using AI-native workflows, you can dismantle traditional language barriers, increase viewer retention, and easily turn a single creative effort into a multi-market global campaign.
Understanding the Mechanics: How AI Video Translation Actually Works
AI video translation has evolved from robotic voiceovers to natural, voice-cloned dubbing, enabling modern content teams to scale their global audience footprint without the high budgets of traditional recording studios. Today, cloud-based automated dubbing engines process audio and video assets through a highly coordinated, multi-stage machine learning pipeline. Instead of a single monolithic model handling the entire process, translation platforms orchestrate several specialized deep learning networks. This modular approach ensures that the localized video retains the precise meaning, emotional nuance, and vocal identity of the original speaker, all while completing the process in a fraction of the time required by a professional recording studio.
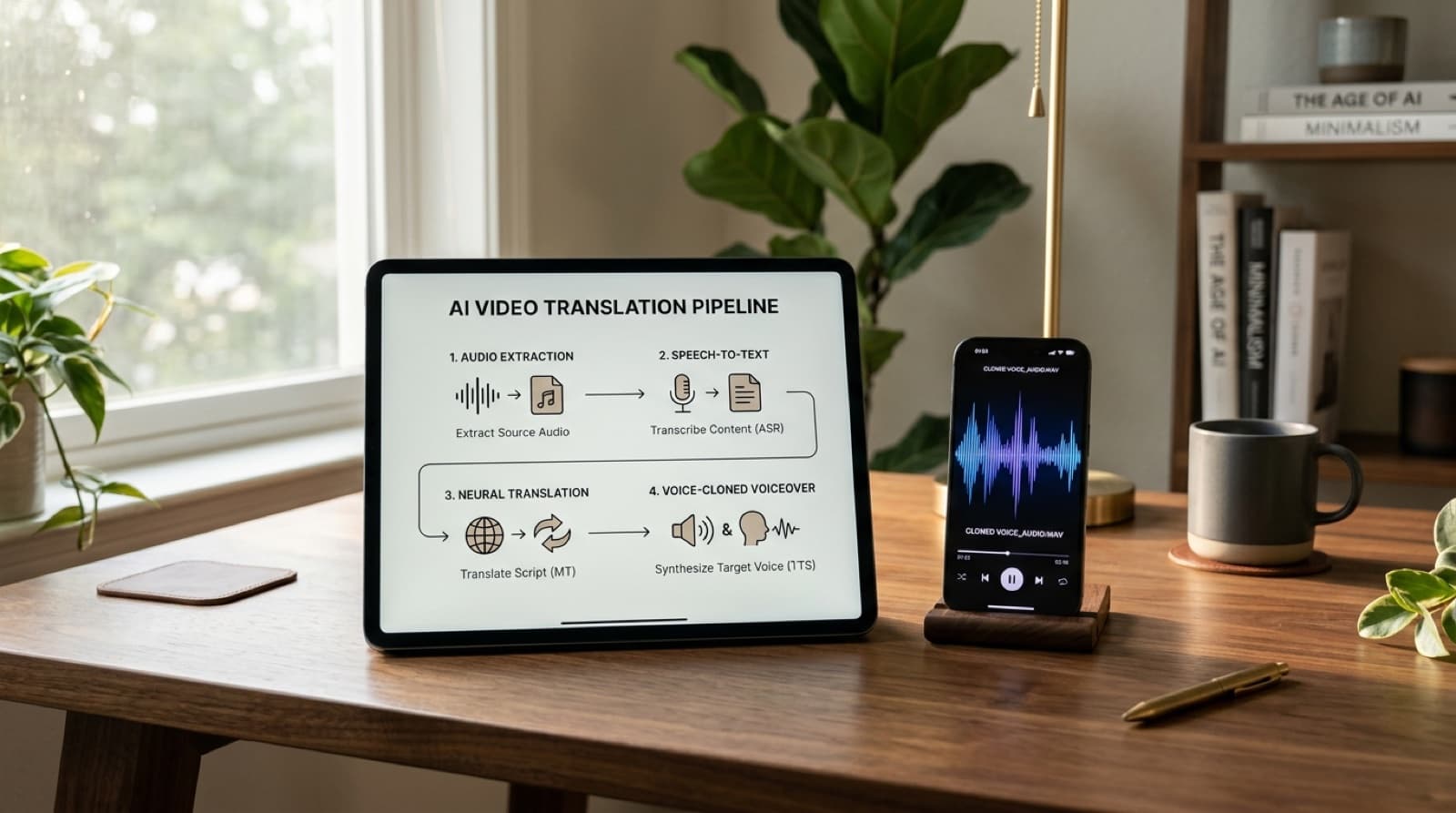
The Three-Pillar Pipeline: ASR, NMT, and Speech Synthesis
The core mechanics of modern automated video translation rely on three fundamental technologies working in sequence. Each phase is critical to converting the spoken dialogue from the source language into a natural-sounding, translated voiceover.
- Automatic Speech Recognition (ASR): The first stage extracts the audio track from the video file and runs it through an advanced speech-to-text model. This model identifies the spoken words, accounts for regional accents or dialects, and generates a time-coded transcript of the conversation.
- Neural Machine Translation (NMT): Once the transcript is finalized, NMT engines analyze the entire text in context rather than translating word-by-word. This allows the system to preserve localized idioms, grammar rules, and cultural context across different language pairs.
- Neural Speech Synthesis and Voice Cloning: In the final stage, text-to-speech models convert the translated script back into spoken audio. Advanced platforms clone the original speaker's vocal characteristics, matching their tone, pitch, and emotion in the new language.
The adoption of these technologies has driven substantial growth in the localization industry. Indeed, the AI language translation market reached 2.34 billion dollars in 2024, representing a compound annual growth rate of 24.9% from the previous year[2]. This massive market expansion is heavily supported by the dominance of Neural Machine Translation, which accounted for 48.67% of the translation market share in 2024[2]. As these models continue to train on massive multilingual datasets, the accuracy and naturalness of automated dubbing will only increase, driving even higher business confidence in these workflows.
For creators and content teams looking to leverage this pipeline, platforms like Dictem make the entire process accessible. Through Dictem Studio, users can seamlessly manage ASR, translation, and high-fidelity voice synthesis in over 100 languages. Whether you are transitioning to advanced video synchronization or looking to scale your reach with a high-quality multilingual voiceover strategy, modern cloud-based workflows remove the traditional barriers of manual dubbing. This automated orchestration lets you create content once, localize it everywhere, and scale your brand to global audiences efficiently.
Beyond Simple Voiceovers: The Power of AI Voice Cloning and Dubbing
In the early days of digital media, translating video content meant choosing between dry, robotic text-to-speech voiceovers or investing in expensive traditional studio dubbing. For decades, production houses, podcast networks, and video creators spent massive budgets to hire foreign-language voice actors, rent professional recording booths, and manually synchronize audio tracks. Today, advanced artificial intelligence has transformed this landscape. Modern content teams can now move beyond robotic audio to deliver high-quality, natural-sounding multilingual content. By leveraging tools that support AI video dubbing, creators can retain their original tone, scale their global presence, and connect deeply with international audiences without traditional overhead costs.
Preserving Timbre, Pitch, and Vocal Identity
At the heart of modern dubbing technology lies neural network capability that captures the unique acoustic signature of a human voice. Traditional translation methods inevitably replace the original speaker, breaking the emotional connection and voice brand consistency that took years to build. Modern AI systems solve this by analyzing speaker timbre, pitch variations, and emotional nuance from a short reference audio file. In fact, advanced cloning models require as little as a two-minute recording to generate a highly accurate digital replica that can speak any target language[3]. By maintaining the original speaker's vocal essence across over 100 languages, podcasters, course creators, and audiobook publishers can protect their intellectual property and brand identity while executing global localization strategies.
| Aspect | Traditional Studio Dubbing | AI Voice Cloning & Dubbing |
|---|---|---|
| Financial Budget | Extremely costly, with major feature film localization sometimes exceeding $100,000 per target language [[cite:https://www.heygen.com/blog/how-to-translate-content-with-ai]]. | Extremely accessible, utilizing self-service platforms to translate files at a fraction of traditional studio rates. |
| Turnaround Time | Slow and complex process involving scheduling, casting, and editing across weeks or months. | Automated translation, vocal rendering, and synchronization completed in a matter of minutes. |
| Vocal Consistency | Requires casting different actors, which completely replaces the original voice and compromises the creator's personal brand. | Preserves the original creator's precise voice timbre and emotional performance across all translated files. |
| Visual Alignment | Demands tedious manual editing to line up spoken syllables, often leading to noticeable visual delays. | Uses AI lip-synchronization technology to automatically align the video's mouth movements with the newly generated audio. |
Achieving vocal authenticity is only half the battle; the visual experience must match the auditory changes. Advanced platforms utilize specialized AI lip-synchronization technology to align the speaker's facial movements with the newly translated vocal track. This prevents the distracting visual delays typical of old-school voiceovers. By synchronizing the audio timeline frame-by-frame with the video stream, software solutions like Dictem Studio can dynamically adjust the speaker's on-screen gestures and mouth shapes. The result is a highly polished, natural presentation that makes the speaker appear to have recorded the video directly in the target language, maximizing retention and trust across international markets AI synchronization.
Speed and Savings: Analyzing the ROI of AI Localization vs. Traditional Studios
Traditional video localization has long been a privilege reserved for major entertainment studios with massive budgets. For independent podcasters, video creators, and audiobook publishers, the high barriers to entry made international expansion practically impossible. However, the landscape is shifting rapidly. The global machine translation market size was estimated at USD 978.2 million in 2022 and is projected to reach USD 2,719.0 million by 2030[4]. This explosive growth is driven by the transition from traditional, highly manual translation processes to sophisticated AI-powered workflows. By leveraging platforms like Dictem Studio, content teams can now bypass physical recording booths entirely, converting a single video or podcast into dozens of foreign languages with unprecedented speed and efficiency.
Traditional Studio Workflows vs. Cloud-Based AI Platforms
| Expense Category | Traditional Recording Studio | AI-Powered Workspace |
|---|---|---|
| Engineering and Actor Fees | Charged hourly, ranging from hundreds to thousands of dollars per session | Included in a predictable software subscription model |
| Turnaround Times | Several weeks for scheduling, recording, and post-production | A few minutes to render high-quality voice-cloned audio |
| Scalability | Highly restricted due to manual scheduling and physical limits | Virtually unlimited, allowing simultaneous multi-language exports |
| Voice Consistency | Requires re-hiring the same voice actors for future updates | Preserves the speaker's original voice profile indefinitely |
The financial contrast is stark. In a traditional setup, localization requires coordination among translators, native-speaking voice actors, sound engineers, and studio space managers. Each participant adds separate fees, pushing the cost of a single dubbed episode into the thousands. In contrast, utilizing AI video dubbing through a web application like Dictem Studio consolidates translation, voice synthesis, and audio mixing into one automated interface. Instead of paying recurring studio engineering fees, content teams utilize automated tools to clone original speaker voices and align translated scripts with video timestamps instantly.
- Zero studio booking overhead: Eliminate the coordinating delays associated with physical recording spaces and actor availability.
- Instant script adjustments: Modify translated scripts and re-generate audio in real time without paying for new studio sessions.
- Vast catalog scalability: Localize an entire archive of past podcasts or videos simultaneously instead of processing them one by one.
- Enhanced emotional connection: Leverage natural voice cloning to keep the author's original personality intact across more than 100 languages.
This radical increase in efficiency enables creators to adopt a systematic approach to global expansion. Publishers and creators no longer need to restrict themselves to a single regional audience. By incorporating a modern localization playbook into their production pipelines, teams can scale their audio catalogs effortlessly. Transitioning to cloud-based multilingual voiceovers allows modern content brands to minimize operational costs while maximizing their international audience reach, turning a cost center into a direct driver of global growth.
Step-by-Step Workflow: How Content Teams Localize Video at Scale
As video consumption scales across different countries, traditional translation workflows are proving too slow and expensive for modern marketing teams. Industry data reveals a massive shift: around 39% of marketers now incorporate machine translation into their localization strategies, with an impressive 83% expressing confidence in the overall quality of these automated results[5]. To successfully scale global reach, professional teams are adopting a modern localization playbook that blends AI speed with quality control, converting a single video into dozens of languages simultaneously.
Step 1: Audio Optimization and Source Preparation
The foundation of high-quality translation begins before any processing starts. Content teams should export clean audio tracks with minimal background noise and music. Separating the vocal track from sound effects ensures that the AI engines can accurately transcribe and translate every word. Tools like Dictem Studio perform exceptionally well when given clean speech feeds, allowing the synthetic voice clones to match the emotional resonance and vocal tone of the original speaker with incredible accuracy.
Step 2: Human-in-the-Loop Review for Brand Term Accuracy
While AI speech translation is faster than traditional studio recording, preserving brand identity requires a human-in-the-loop approach. Marketing terms, specialized jargon, and trademarked names can easily be mistranslated by automated algorithms. Content teams should use an editing interface to review the transcribed text, define a glossary, and correct any cultural nuances. This validation phase ensures 100% brand safety before the AI generates the finalized dubbing in the target languages.
- Source Preparation: Export clean voice tracks and remove background hiss to give AI voice synthesis engines the best starting point.
- Glossary Definition: Pre-define brand names and industry jargon to guarantee consistent translation across all languages.
- Human Validation: Review the translated transcription before voice rendering to adjust tone and preserve cultural intent.
- Voice Cloning: Apply cloned voices to the corrected transcript to maintain the speaker's original character and charm.
- Timing Calibration: Synchronize the synthesized audio back with the video to prevent any unnatural delays or pacing issues.
Step 3: Multi-Track Distribution Strategy
Once localized files are ready, distributing them efficiently is the final hurdle. For video platforms, leveraging multi-track audio is a massive breakthrough. Instead of creating and managing separate channels for every localized market, you can upload multiple audio tracks to a single video. This strategy improves channel authority, consolidates views, and maximizes search visibility across regions. Implementing a robust YouTube translation strategy helps your channel gain global traction without fracturing your audience footprint.
By utilizing automated tools like Dictem Studio, content teams can move from zero to dozens of localized video versions in hours instead of weeks. Whether deciding between AI dubbing or simple subtitles, having an automated pipeline allows your brand to grow globally while maintaining the highest level of trust and engagement.
Häufig gestellte Fragen
How accurate is AI video translation?
Modern AI translation engines achieve impressive baseline accuracy, especially when using specialized workspaces like Dictem Studio. For technical or branded content, teams employ a hybrid approach - starting with high-quality AI translation and finalizing with a quick human review to ensure 100% conceptual accuracy.
Can AI translate my video and keep my actual voice?
Yes, neural voice cloning technology makes this possible. By analyzing a brief sample of your original audio, advanced algorithms mimic your timber, pitch, and natural speech rhythm, allowing you to speak fluently in over 38 different languages while keeping your personal vocal brand.
How does AI video dubbing compare to traditional recording studios?
Traditional dubbing requires voice talent, studio rentals, sound engineers, and days of back-and-forth editing, costing thousands of dollars. AI translation platforms automate this process, allowing you to localize hours of video content in minutes for a tiny fraction of the cost.
Which platforms support multi-language video audio tracks?
Major hosting platforms are rolling out native multi-language audio tools. YouTube lets creators upload multiple audio tracks to a single video link, while main podcast directories support localized RSS feeds to let international listeners seamlessly hear content in their preferred language.
How long does it take to translate a standard video with AI?
With modern tools like Dictem Studio, generating transcription, translation, and localized synthetic voice tracks takes only a few minutes. Reviewing scripts for branding and exporting the finished video can be done in under an hour, making same-day international publication a reality.
Can AI translation handle multiple distinct speakers in one video?
Yes. Advanced localization models use speaker diarization to recognize when different individuals are talking. The software then applies distinct, customized voices or separately cloned voices to each speaker, preserving conversational clarity and story depth.
Quellen
Ready to go global?
Translate, re-voice, and package your content for every language, with Dictem.
Open Dictem Studio